Forecast Model Run Collections (FMRC)¶
There are many ways one might index weather forecast output. These different ways of constructing views of a forecast data are called “Forecast Model Run Collections” (FMRC).
“Model Run” : a single model run.
“Constant Offset” : all values for a given lead time.
“Constant Forecast” : all forecasts for a given time in the future.
“Best Estimate” : A best guess stitching together the analysis or initialization fields for past forecasts with the latest forecast.
For reference, see this classic image:
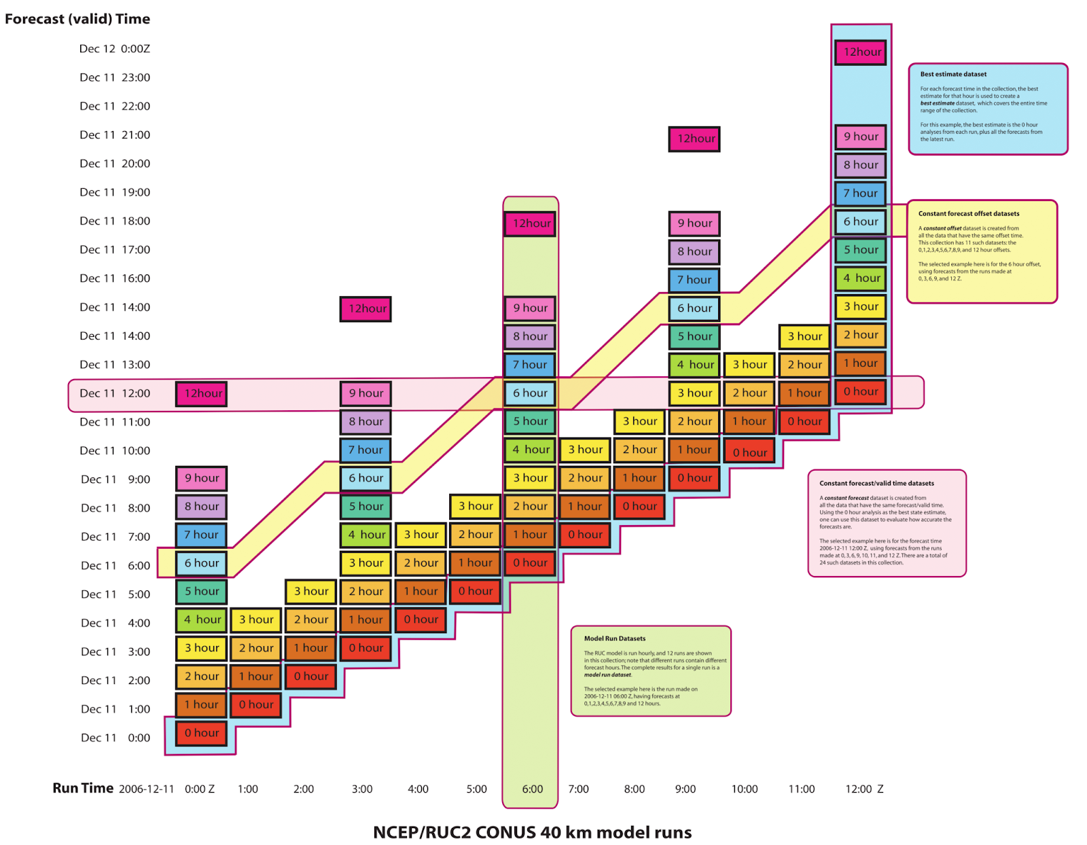
Assume that a data cube has been constructed with forecast_reference_time (commonly time) and forecast_period (commonly step or lead) as dimensions.
Then the more complex indexing patterns — “Constant Forecast” or “Best Estimate” — are achievable with numpy-style vectorized indexing. This notebook demonstrates all 4 “FMRC” indexing patterns with a custom Xarray index.
Note
Some complexity arises from models like HRRR where not all runs are the same length (unlike GFS).
This complexity is handled by hardcoding in what data is available for each model: for example, with HRRR we know there are 49 steps available every 6 hours, and 19 steps otherwise.
I don’t know of any standard to encode this information on disk. Please reach out if you do know.
Create an example data cube¶
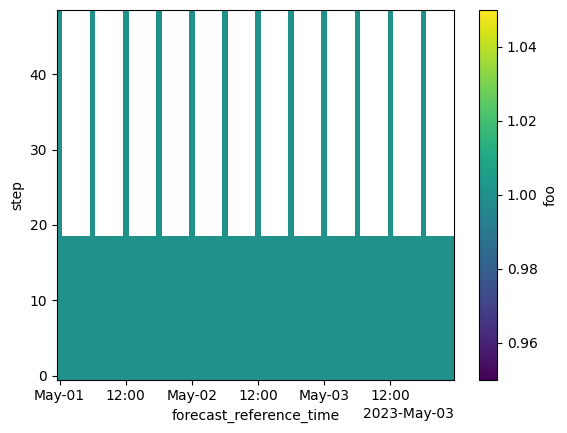
Here is a synthetic year-long dataset that mimics the HRRR forecasts.
Usually individual files describe a single step for a single forecast initialized at time. ds below models a datacube where such files have been concatenated along the step and time dimensions.
import rolodex.forecast
from rolodex.forecast import (
BestEstimate,
ConstantForecast,
ConstantOffset,
ForecastIndex,
Model,
ModelRun,
)
<xarray.Dataset> Size: 137MB
Dimensions: (time: 8760, step: 49, x: 40)
Coordinates:
* time (time) datetime64[us] 70kB 2023-01-01 ... 2023-12-31T23:00:00
* step (step) timedelta64[s] 392B 00:00:00 01:00:00 ... 2 days 00:00:00
Dimensions without coordinates: x
Data variables:
foo (time, step, x) float64 137MB 1.0 1.0 1.0 1.0 ... nan nan nan nan
Attributes:
description: Example HRRR-like dataset(ds.foo.isel(x=20).sel(time=slice("2023-May-01", "2023-May-03")).drop_vars("step").plot(x="time"))
<matplotlib.collections.QuadMesh at 0x7ff279afa660>
Create a ForecastIndex¶
We choose to model forecast datasets by adding a lazy “valid time” variable. This allows indexing syntax like .sel(valid_time=ConstantOffset(...)) whereConstantOffset is a FMRC-style ‘indexer’.
An alternative design would be to enable indexing with ds.fcst.constant_offset(...). The underlying concepts and logic remains the same, and does not need a custom Index.
ds.coords["valid_time"] = rolodex.forecast.create_lazy_valid_time_variable(
reference_time=ds.time, period=ds.step
)
# set the new index
newds = ds.drop_indexes(["time", "step"]).set_xindex(
["time", "step", "valid_time"], ForecastIndex, model=Model.HRRR
)
newds
<xarray.Dataset> Size: 141MB
Dimensions: (time: 8760, step: 49, x: 40)
Coordinates:
* time (time) datetime64[us] 70kB 2023-01-01 ... 2023-12-31T23:00:00
* step (step) timedelta64[s] 392B 00:00:00 01:00:00 ... 2 days 00:00:00
* valid_time (time, step) datetime64[us] 3MB ...
Dimensions without coordinates: x
Data variables:
foo (time, step, x) float64 137MB 1.0 1.0 1.0 1.0 ... nan nan nan
Indexes:
┌ time ForecastIndex
│ step
└ valid_time
Attributes:
description: Example HRRR-like dataset“Standard” selection¶
The usual indexing patterns along time and step individually still work.
<xarray.Dataset> Size: 21MB
Dimensions: (time: 5832, step: 11, x: 40)
Coordinates:
* time (time) datetime64[us] 47kB 2023-05-03 ... 2023-12-31T23:00:00
* step (step) timedelta64[s] 88B 02:00:00 03:00:00 ... 12:00:00
* valid_time (time, step) datetime64[us] 513kB ...
Dimensions without coordinates: x
Data variables:
foo (time, step, x) float64 21MB 1.0 1.0 1.0 1.0 ... 1.0 1.0 1.0 1.0
Indexes:
┌ valid_time ForecastIndex
│ time
└ step
Attributes:
description: Example HRRR-like datasetFMRC indexing¶
For all cases, ForecastIndex knows how to select values so there is no missing data i.e. it only returns time stamps for which there exists a forecast.
We’ve told the index that this model is HRRR — the HRRR output characteristics are hard-coded in the index code. This could be refactored a little.
Other models, like GFS, don’t require any configuration.
Note
In the examples below, we will assert not subset.foo.isnull().any().item() to make sure only valid timesteps are returned after indexing
BestEstimate¶
subset = newds.sel(valid_time=BestEstimate())
assert not subset.foo.isnull().any().item()
subset
<xarray.Dataset> Size: 3MB
Dimensions: (valid_time: 8778, x: 40)
Coordinates:
* valid_time (valid_time) datetime64[us] 70kB 2023-01-01 ... 2024-01-01T17...
time (valid_time) datetime64[us] 70kB 2023-01-01 ... 2023-12-31T23...
step (valid_time) timedelta64[s] 70kB 00:00:00 00:00:00 ... 18:00:00
Dimensions without coordinates: x
Data variables:
foo (valid_time, x) float64 3MB 1.0 1.0 1.0 1.0 ... 1.0 1.0 1.0 1.0
Attributes:
description: Example HRRR-like datasetConstantForecast¶
subset = newds.sel(valid_time=ConstantForecast("2023-12-29"))
assert not subset.foo.isnull().any().item()
subset
<xarray.Dataset> Size: 8kB
Dimensions: (time: 24, x: 40)
Coordinates:
* time (time) datetime64[us] 192B 2023-12-27 ... 2023-12-29
step (time) timedelta64[s] 192B 2 days 00:00:00 ... 00:00:00
valid_time datetime64[us] 8B 2023-12-29
Dimensions without coordinates: x
Data variables:
foo (time, x) float64 8kB 1.0 1.0 1.0 1.0 1.0 ... 1.0 1.0 1.0 1.0
Attributes:
description: Example HRRR-like datasetIndexing ‘valid_time’ with a scalar is identical to ConstantForecast (indexing valid_time with tuples, lists, or arrays is not allowed).
newds.sel(valid_time="2023-12-29")
<xarray.Dataset> Size: 8kB
Dimensions: (time: 24, x: 40)
Coordinates:
* time (time) datetime64[us] 192B 2023-12-27 ... 2023-12-29
step (time) timedelta64[s] 192B 2 days 00:00:00 ... 00:00:00
valid_time datetime64[us] 8B 2023-12-29
Dimensions without coordinates: x
Data variables:
foo (time, x) float64 8kB 1.0 1.0 1.0 1.0 1.0 ... 1.0 1.0 1.0 1.0
Attributes:
description: Example HRRR-like datasetConstantOffset¶
subset = newds.sel(valid_time=ConstantOffset("32h"))
assert not subset.foo.isnull().any().item()
subset
<xarray.Dataset> Size: 491kB
Dimensions: (time: 1460, x: 40)
Coordinates:
* time (time) datetime64[us] 12kB 2023-01-01 ... 2023-12-31T18:00:00
* valid_time (time) datetime64[us] 12kB 2023-01-02T08:00:00 ... 2024-01-02...
step timedelta64[s] 8B 1 days 08:00:00
Dimensions without coordinates: x
Data variables:
foo (time, x) float64 467kB 1.0 1.0 1.0 1.0 1.0 ... 1.0 1.0 1.0 1.0
Attributes:
description: Example HRRR-like datasetModelRun¶
For HRRR, the 03Z forecast only has 19 timesteps
subset = newds.sel(valid_time=ModelRun("2023-06-30 03:00"))
assert subset.sizes["step"] == 19
assert not subset.foo.isnull().any().item()
subset
<xarray.Dataset> Size: 6kB
Dimensions: (step: 19, x: 40)
Coordinates:
* step (step) timedelta64[s] 152B 00:00:00 01:00:00 ... 18:00:00
* valid_time (step) datetime64[us] 152B 2023-06-30T03:00:00 ... 2023-06-30...
time datetime64[us] 8B 2023-06-30T03:00:00
Dimensions without coordinates: x
Data variables:
foo (step, x) float64 6kB 1.0 1.0 1.0 1.0 1.0 ... 1.0 1.0 1.0 1.0
Attributes:
description: Example HRRR-like datasetwhile the 06Z forecast has 49 timesteps
subset = newds.sel(valid_time=ModelRun("2023-06-30 06:00")) # 49
assert subset.sizes["step"] == 49
assert not subset.foo.isnull().any().item()
subset
<xarray.Dataset> Size: 16kB
Dimensions: (step: 49, x: 40)
Coordinates:
* step (step) timedelta64[s] 392B 00:00:00 01:00:00 ... 2 days 00:00:00
* valid_time (step) datetime64[us] 392B 2023-06-30T06:00:00 ... 2023-07-02...
time datetime64[us] 8B 2023-06-30T06:00:00
Dimensions without coordinates: x
Data variables:
foo (step, x) float64 16kB 1.0 1.0 1.0 1.0 1.0 ... 1.0 1.0 1.0 1.0
Attributes:
description: Example HRRR-like dataset